The second chapter is programming technology, this article is the 2.1.3 callback function.
> > > > 2.1.3 Callback function
> > > 1. Layered design
Hierarchical design is to divide the software into modules with some subordinate relationship. Since each layer is relatively independent, as long as the interface between layers is defined, each layer can be implemented separately. For example, designing a safe electronic lock, the hardware part of which includes keyboard, display, buzzer, lock and memory drive circuit, so the software is divided into three parts: hardware driver layer, virtual layer and application layer. Each large module can be divided into several small modules. The following will be explained by taking a keyboard scan as an example.
(1) hardware driver layer
The hardware driver layer is at the bottom of the module and works directly with the hardware. Its task is to identify which key is pressed, to implement some software that is closely related to the hardware circuit, and more advanced functions will be implemented at other layers. Although the hardware driver layer can directly reach the application layer, due to various changes in the hardware circuit, if the application layer directly operates the hardware driver layer, the application layer is bound to depend on the hardware layer, and the best method is to add a virtual layer to deal with hardware changes. Obviously, as long as the keyboard scanning method is unchanged, the generated key values ​​will remain unchanged, and the software of the virtual layer will never change.
(2) Virtual layer
It is divided according to the requirements of the application layer, mainly used to shield the details and changes of the object, then the application layer can be implemented in a unified way. Even if the control method changes, there is no need to rewrite the application layer code.
(3) Application layer
The application layer is at the top of the module and is directly used for function implementation. For example, the application layer has only one "human-computer interaction" module externally. Of course, several modules can be divided internally for use. The relationship between the data transfer between the three layers is very clear, that is, the application layer -> virtual layer -> hardware driver layer, as shown in Figure 2.2, the solid line in the figure represents the dependency, that is, the application layer depends on the virtual layer, and the virtual layer depends on Hardware driver layer. A layer-based architecture has the following advantages:
Reduce the complexity of the system: Since each layer is relatively independent, the layers interact with each other through well-defined interfaces, each layer can be implemented separately, thus reducing the coupling between modules;
Isolation changes: Software changes usually occur at the top and bottom layers. The top layer is the graphical user interface. Changes in requirements usually directly affect the user interface. Most new and old versions of the software will vary greatly in the user interface. The bottom layer is hardware. The change of hardware is faster than the development of software. The layered design can separate these changes, so that their changes will not have a big impact on other parts;
Conducive to automated testing: Because each layer has independent features, it is easier to write test cases;
It helps to improve the portability of the program: the different parts of the platform are placed in separate layers through layered design. For example, the lower module is a wrapper layer that wraps the interface provided by the operating system, and the upper layer is a graphical user interface implemented for different platforms. When porting to different platforms, only different parts need to be implemented, and the middle layer can be reused.
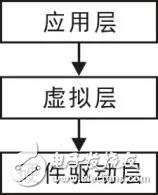
Figure 2.2 Three-layer structure
The application layer is at the top of the module and is directly used for function implementation. For example, the application layer has only one "human-computer interaction" module externally. Of course, several modules can be divided internally for use. The relationship between the data transfer between the three layers is very clear, that is, the application layer -> virtual layer -> hardware driver layer, as shown in Figure 2.2, the solid line in the figure represents the dependency, that is, the application layer depends on the virtual layer, and the virtual layer depends on Hardware driver layer. A layer-based architecture has the following advantages:
Reduce the complexity of the system: Since each layer is relatively independent, the layers interact with each other through well-defined interfaces, each layer can be implemented separately, thus reducing the coupling between modules;
Isolation changes: Software changes usually occur at the top and bottom layers. The top layer is the graphical user interface. Changes in requirements usually directly affect the user interface. Most new and old versions of the software will vary greatly in the user interface. The bottom layer is hardware. The change of hardware is faster than the development of software. The layered design can separate these changes, so that their changes will not have a big impact on other parts;
Conducive to automated testing: Because each layer has independent features, it is easier to write test cases;
It helps to improve the portability of the program: the different parts of the platform are placed in separate layers through layered design. For example, the lower module is a wrapper layer that wraps the interface provided by the operating system, and the upper layer is a graphical user interface implemented for different platforms. When porting to different platforms, only different parts need to be implemented, and the middle layer can be reused.
> > > Â 2. Isolation changes
(1) Hollywood Principles (Hollywood)
Modules like keyboard scanning, the commonality is the calling relationship between layers, it is impossible to change with time, even if the upper and lower layers form a dependency relationship, the direct calling method is the simplest. In order to reduce the coupling between layers, the communication between layers must be carried out according to certain rules. That is, the upper layer can directly call the function provided by the lower layer, but the lower layer cannot directly call the function provided by the upper layer, and the layer and the layer cannot be called cyclically. Because the circular dependencies between layers can seriously hinder the reusability and scalability of software, each layer in the system cannot form a reusable component independently. Although the upper layer can also call the function provided by the adjacent lower layer, it cannot be called across layers. That is, the lower module implements the interface declared in the upper module and called by the high-level module. This is the famous Hollywood extension principle: "Don't call me, let me call you." When the lower layer needs to pass data to the upper layer, then Use the callback function pointer interface to isolate changes. By inverting dependent interface ownership, a more flexible, more durable, and easier to modify structure is created.
In fact, the expression of the callback function provided by the upper module (that is, the caller) is to call another function through the function pointer in the lower module, that is, the address of the callback function is used as an argument to initialize the formal parameters of the lower module, and the lower module is Call this function at some point. This function is a callback function, as shown in Figure 2.3. There are two ways to call it:
In the function of the upper module A calling the lower module B, the callback function C is directly called;
Using the registration method, when an event occurs, the lower module calls the callback function.
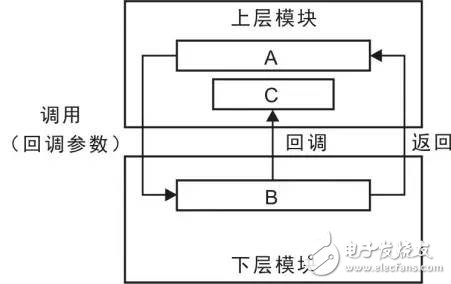
Figure 2.3 Use of callback function
At the time of initialization, the upper module A passes the address of the callback function C as an argument to the lower module B. In operation, this callback function is called when the underlying module needs to communicate with the upper module. The calling mode is A→B→C, and the upper module A calls the lower module B. During the execution of B, the callback function is called to return the information to the upper module. For the upper module, C not only monitors the running status of B, but also interferes with the operation of B, which is essentially the upper module calling the lower module. Since the callback function is added, dynamic binding can be implemented on the fly. The following is an example of sorting an arbitrary type of data by a standard bubble sort function.
(2) Data comparison function
Assuming that the data to be sorted is int type, it is possible to make a process of exchanging data by comparing the sizes of adjacent data. When two pointers e1 and e2 pointing to an int variable are given, the comparison function returns a number. If *e1 is less than *e2, the returned number is negative; if *e1 is greater than *e2, the returned number is a positive number; if *e1 is equal to *e2, then the returned number is 0, as shown in Listing 2.4.
Listing 2.4 compare_int() data comparison function
1 int compare_int(const int *e1, const int *e2)
2 {
3 return *e1 - *e2; // Â Ascending comparison
4 }
5
6 int compare_int(const int *e1, const int *e2)
7 {
8 return *e2 - *e1; // Â Descending comparison
9 }
Since pointers of any data type can assign values ​​to void* pointers, you can take advantage of this feature and use the void* pointer as a parameter to the data comparison function. When the function's formal parameter is declared as void *, although the bubbleSort() bubble sort function does not know what type of data the caller will pass inside, but the caller knows the type of the data and the method of operation on the data, then The caller writes a data comparison function.
Since the caller must decide which data comparison function to call according to the actual situation at runtime, the function prototype is as follows according to the requirements of the comparison operation:
Typedef int (*COMPARE)(const void *e1, const void *e2);
Among them, e1 and e2 are pointers to two values ​​that need to be compared. When the return value is < 0, it means e1 < e2; when the return value = 0, it means e1 = e2; when the return value is > 0, it means e1 > e2.
When declared with a typedef, COMPARE becomes a function pointer type. With a type, you can define a function pointer variable of that type. such as:
COMPARE compare;
At this point, as long as the function name (for example, compare_int) is used as the formal parameter of the argument initialization function, the corresponding data comparison function can be called. such as:
COMPARE compare=compare_int;
Although the compiler sees a compare, the caller implements a number of different types of compares, which can change the behavior of the function according to the type in the interface function. The implementation of the general data comparison function is shown in Listing 2.5.
Listing 2.5 The implementation of the compare data comparison function
1 int compare_int(const void *e1, const void *e2)
2 {
3 return (*((int *)e1) - *((int *)e2)); // Â Ascending comparison
4 }
5
6 int compare_int_invert(const void *e1, const void *e2)
7 {
8 return *(int *)e2 - *(int *)e1; // Â Descending comparison
9 }
10
11 int compare_vstrcmp(const void *e1, const void *e2)
12 {
13 return strcmp(*(char**)e1, *(char**)e2); // Â String comparison
14 }
Note that if e1 is a large positive number and e2 is a large negative number, or vice versa, the calculation may overflow. Since it is assumed here that they are all positive integers, the risk is avoided.
Since the argument to the function is declared as a void * type, the data comparison function is no longer dependent on the specific data type. You can separate the changes in the algorithm, whether it is ascending or descending or string comparison depends entirely on the callback function. Note that the reason why you can't directly use strcmp() as a string comparison, because bubbleSort() passes the address of an array element of type char ** &array[i], instead of array[i] of type char*.
(3) bubbleSort () bubble sorting function
The standard function bubbleSort() is a classic example of using function pointers in C. A function that sorts an array of any type, where the size of the individual elements and the functions of the elements to be compared are given. Its prototype was initially defined as follows:
bubbleSort (parameter list);
Since bubbleSort() is sorting the data in the array, bubbleSort() must have a parameter to hold the starting address of the array, and a parameter to hold the number of elements in the array. In order to generalize or store the void * type element in the array, you can use the array to store any type of data passed by the user, so use the void * type parameter to save the starting address of the array. Its function prototype is as follows:
bubbleSort(void *base, size_t nmemb);
Since the type of the array is unknown, the length of the elements in the array is also unknown, and a parameter is also needed to save. Its function prototype evolved into:
bubbleSort(void *base, size_t nmemb, size_t size);
Among them, size_t is a predefined type in the C standard library, specifically for saving the size of variables. The parameters base and nmemb identify this array, which is used to store the starting address of the array and the number of elements in the array. The size stores the size of a single element when it is packed.
At this point, if you pass a pointer to compare() as a parameter to bubbleSort(), you can "callback" compare() to compare the values. Since sorting is an operation on data, bubbleSort() has no return value, its type is void, and the bubbleSort() function interface is shown in Listing 2.6.
Listing 2.6 bubbleSort() bubble sort function interface (bubbleSort.h)
1 #pragma once;
2 void bubbleSort(void *base, size_t nmemb, size_t size, COMPARE compare);
Although most beginners also choose callback functions, they often use global variables to hold intermediate data. The solution proposed here is to pass a parameter called "callback function context" to the callback function whose variable name is base. In order to accept any data type, select void * to represent this context. "Context" means that if an int type value is passed in, the int type data comparison function is called back; if a string is passed in, the string comparison function is called back.
When bubbleSort() declares base as a void * type, it allows bubbleSort() to use the same code to support different types of data comparisons. The key is the type field, which allows the type of data at runtime. Call different functions. This behavior of associating a function body with a function call at runtime based on the type of data is called dynamic binding, so the binding of a function occurs at runtime rather than at compile time, which is said to be polymorphic. Obviously, polymorphism is a runtime binding mechanism whose purpose is to bind the function name to the implementation code of the function. The name of a function is closely related to its entry address. The entry address is the starting address of the function in memory, so polymorphism is the runtime binding mechanism that dynamically binds the function name to the function entry address. bubbleSort() See Appendix 2.7 and Listing 2.8 for the interface and implementation.
Program list  2.7  bubbleSort() interface (bubbleSort.h)
1 #pragma once
2 #include
3
4 typedef int(*COMPARE)(const void * e1, const void *e2);
5 void bubbleSort(void * base, size_t nmemb, size_t size, COMPARE compare);
Program list  2.8  Implementation of the bubbleSort() interface (bubbleSort.c)
1 #include"bubbleSort.h"
2
3 void byte_swap(void *pData1, void *pData2, size_t stSize)
4 {
5 unsigned char *pcData1 = pData1;
6 unsigned char *pcData2 = pData2;
7 unsigned char ucTemp;
8
9 while (stSize--){
10 ucTemp = *pcData1; *pcData1 = *pcData2; *pcData2 = ucTemp;
11 pcData1++; pcData2++;
12 }
13 }
14
15 void bubbleSort(void * base, size_t nmemb, size_t size, COMPARE compare)
16 {
17 int hasSwap=1;
18
19 for (size_t i = 1; hasSwap&& < <ememb; i++) {
20 hasSwap = 0;
21 for (size_t j = 0; j < numData - 1; j++) {
22 void *pThis = ((unsigned char *)base) + size*j;
23 void *pNext = ((unsigned char *)base) + size*(j+1);
24 if (compare(pThis, pNext) > 0) {
25 hasSwap = 1;
26 byte_swap(pThis, pNext, size);
27 }
28 }
29 }
30 }
Static type and dynamic type
The static and dynamic type refers to the time when the name is bound to the type. If all the variables and expression types are fixed at compile time, it is called static binding; if all variables and expressions are of type until Known at runtime, it is called dynamic binding.
Suppose you want to implement a bubble sort function for any data type and simply test it. The requirement is that the same function can be arranged from large to small, from small to large, and supports multiple data types at the same time. such as:
Int array[] = {39, 33, 18, 64, 73, 30, 49, 51, 81};
Obviously, just call the comparison function's entry address compare_int to compare, you can call bubbleSort():
Int array[] = {39, 33, 18, 64, 73, 30, 49, 51, 81};
bubbleSort(array, numArray , sizeof(array[0]), compare_int);
When the number is small, the performance of all sorting algorithms is not much different, because the advanced algorithm only shows a significant improvement in performance when the number of elements is more than 1000. In fact, in more than 90% of cases, the number of elements we store is only tens to hundreds, bubble sorting may be a better choice, bubbleSort () implementation and use of the sample program is detailed in Listing 2.9.
Listing 2.9 bubbleSort() bubble sorting sample program
1 #include
2 #include
3 #include"bubbleSort.h"
4
5 int compare_int(const void * e1, const void * e2)
6 {
7 return *(int *)e1 - *(int *)e2;
8 }
9
10 int compare_int_r(const void * e1, const void * e2)
11 {
12 return *(int *)e2 - *(int *)e1 ;
13 }
14
15 int compare_str(const void * e1, const void *e2)
16 {
17 return strcmp(*(char **)e1, *(char **)e2);
18 }
19
20 void main()
twenty one {
22 int arrayInt[] = { 39, 33, 18, 64, 73, 30, 49, 51, 81 };
23 int numArray = sizeof(arrayInt) / sizeof(arrayInt[0]);
24 bubbleSort(arrayInt, numArray, sizeof(arrayInt[0]), compare_int);
25 for (int i = 0; i
26 printf("%d ", arrayInt[i]);
27 }
28 printf("");
29
30 bubbleSort(arrayInt, numArray, sizeof(arrayInt[0]), compare_int_r);
31 for (int i = 0; i
32 printf("%d ", arrayInt[i]);
33 }
34 printf("");
35
36 char * arrayStr[] = { "Sunday", "Monday", "Tuesday", "Wednesday", "Thursday", "Friday", "Saturday" };
37 numArray = sizeof(arrayStr) / sizeof(arrayStr[0]);
38 bubbleSort(arrayStr, numArray, sizeof(arrayStr[0]), compare_str);
39 for (int i = 0; i < numArray; i++) {
40 printf("%s", arrayStr[i]);
41 }
42 }
It can be seen that both the caller main() and the compare_int() callback function belong to the upper module, and the bubbleSort() belongs to the lower module. When the upper module calls the lower module bubbleSort(), the address compare_int of the callback function is passed as a parameter to bubbleSort(), and then compare_int() is called. Obviously, using the parameter passing callback function, the lower module does not need to know which function of the upper module needs to be called, thereby reducing the connection between the upper and lower layers, so that the upper and lower layers can be modified independently without affecting the implementation of another layer of code. In this way, each time you call bubbleSort(), bubbleSort() does not have to be modified as long as you give a different function name as an argument.
The biggest advantage of using the callback function is that it facilitates the layered design of software modules and reduces the coupling between software modules. That is, the callback function can isolate the caller from the callee, and the caller does not need to care who is the callee. When a specific event or condition occurs, the caller will call the callback function with the function pointer to handle the event.
High temperature thermocouple slip ring with German and Japanese imports of key materials, can be used in high temperature environment rotate 360 degrees to transmit current and thermocouple signal, can be long-term stability in 100 ~ 250 ℃ high temperature environment, it is mainly used for hot roller, the high temperature environment, such as heating device, suffered long-term complex field practice test, transmission performance is stable and the quality.
High Temperature Slip Ring,Taidacent Slip Ring,Slip Ring Capsule,Fiber Brush Slip Ring
Dongguan Oubaibo Technology Co., Ltd. , https://www.sliproubo.com