Why do you talk about SLAM today? The main reason is that there are companies in the country that announce this pit. In the United States, the AR cloud is also one of the hottest areas in the field. The AR cloud that is imagined by many companies that are in the direction of the AR cloud is also based on SLAM. What do you think? Welcome message discussion
As we all know, SLAM, that is, simultaneous positioning and map construction, mainly solves the problem of how to carry out the orientation of its own position in an unknown environment and construct a map of the three-dimensional environment at the same time. It is a basic problem in the field of robotics and computer vision. Basically, SLAM technology is needed for applications that require positioning and 3D perception. However, SLAM technology has hardly changed in recent years.
Recently, Andrew Davison of the Imperial College in London published a paper that focuses on the gap between the visual perception required by devices such as augmented reality glasses or robots and the actual conditions of real products, and on future space artificial intelligence algorithms. The exploration of computing architecture and hardware development.
Andrew Davison's best-known achievement is his 2003 MonoSLAM system, and he was the first person to show how to build a SLAM system on a single camera. At that time, everyone else thought that building a SLAM system requires a stereoscopic binocular system. Camera kit.
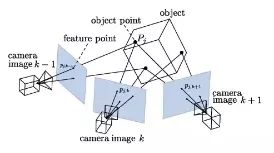
For example, imagine how the future AR system should have spatial memory capabilities. For the user’s location, the people and objects encountered, the user’s virtual notes or other notes placed in space, etc. Recorded. In addition, in order to achieve a wide range of applications, the device should have the size and weight of standard eyewear, and can operate without battery charging all day long.
Obviously, this ideal AR system is far from reachable with current equipment and algorithms. This paper also explains the possible optimization directions for current hardware and algorithms.

The current SLAM technology is mostly the so-called closed-loop SLAM. After capturing new image data from the camera and sensor, the system compares it with the current world model and updates the current world model. The current world model derives from the same update earlier.
All the useful data obtained by this method is derived from sensors (such as depth cameras) and ultimately used for data correlation and tracking in real-time loops.
The paper mentions a new hybrid SLAM system that uses SLAM as a supplement to convolutional neural networks and deep learning: SLAM focuses on geometric issues, while deep learning is the master of perception and recognition. If you want a robot that can walk in front of your fridge without hitting the wall, use SLAM. If you want a robot that can identify items in the refrigerator, use a convolutional neural network. This system also applies to the previously mentioned closed-loop output and may perform better.
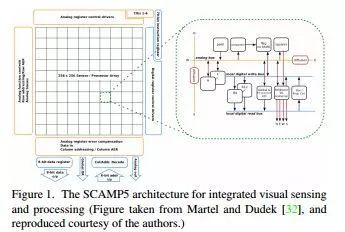
Most future calculations may involve the shaping of world models, which requires a system that constantly changes and improves data storage. In this system, some of the major computational elements are:
Annotation: Emulate the image (for example, CNN).
Rendering: Get intensive forecasts from the world and map to image space.
Tracking: Alignment of predictions with new image data, including finding outliers and detecting independent movements.
Fusion: Re-merging updated geometry and labels
map.
Map Merge: Merges elements into objects, making them smooth and regular.
Reposition/Closed Loop Detection: Detects similarities in the total map.
Mapping consistency optimization, ie fastening closed loop.
Self-learning: The system self-learns from the operation
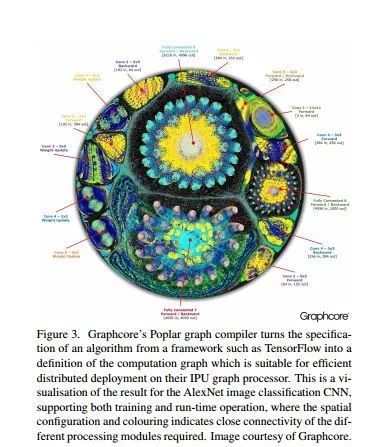
Original: This is a result of visualizing the AlexNet image classification CNN, which supports training and run-time operations, where spatial configuration and shading represent different tight connections that need to be processed. (Don't understand it doesn't matter, this is just an example mentioned in the paper about the world model)
With technological progress, the bottleneck of Moore's Law seems to have begun to appear. It is still difficult to pursue single-core higher-power processors. In SLAM, the parallelism provided by single-instruction, multi-threaded GPUs is also very suitable for real-time vision. The calculation requirements.
Therefore, the paper predicts that the system will have heterogeneous, multi-element, and specialized architectures. In this architecture, low-power operation must be implemented together with high power, and due to the flexibility of the architecture and the huge number of CPUs and GPUs, Increase the amount of useful software running on your system. However, it may also optimize some specialized processors to achieve low-power real-time vision. Of course, system algorithms designed specifically for this architecture will also appear to increase efficiency.
In addition, the capacity of cloud computing resources may continue to expand, and future systems may be connected to the cloud most of the time. The main map will be stored in the cloud where the device will output data as needed. In this case, the things that each device needs to do are theoretically greatly reduced. But this requires the support of high frame rate transmission, which is also a difficult problem to solve.
For the sensor, the data obtained by the sensor is huge but there is redundancy. For example, the data between adjacent pixels in the picture may be very similar, and the information of two adjacent frames of pictures may also be similar. So sometimes huge data processing is not necessary.

Therefore, the paper proposes a method to simplify the data, all sensors are connected to a total processor for preprocessing, but in light of heat dissipation and other issues, instead of embedding a simple processor in the sensor unit, the data is simplified. Get more efficiency.
The paper also stated that in the long-term, due to its real-time nature and wide availability, SLAM has different output and performance levels for different applications, making it particularly difficult to determine a SLAM benchmark by means such as data set evaluation. Therefore, SLAM's benchmarks should go toward the generalization of criteria for predicting tasks that may need to be performed. Possible indicators include:
• Local attitude accuracy in the newly explored area (visual
Mileage drift rate).
• Good mapping of long-term metrics for repetitive areas of gestures.
• Track the percentage of robustness.
• Reposition the percentage of robustness.
• SLAM system delays.
• Precise distance prediction accuracy for each pixel.
• Accuracy of object segmentation.
• Accuracy of object classification.
• AR pixel registration accuracy.
• Scene change detection accuracy.
• Electricity usage.
• Data movement
In short, the author believes that due to the importance of SLAM in various fields, the research on SLAM will continue to be maintained, and these aspects will be optimized.
This paper is based on a summary of the author's understanding of most of the existing SLAM technologies and difficulties. It is of comparative value. Students interested in the original text can also poke and read the original download
Wenzhou Langrun Electric Co.,Ltd , https://www.langrunele.com