Editor's note: Vincent Mühler, maintainer of opencv4nodejs and face-recognition.js, describes how to use a trained neural network model to identify objects in an image in a Node.js environment.

Today we will look at the OpenCV deep neural network module of Node.js.
If you want to release the magic of neural networks to recognize and classify objects in an image but have no idea how deep learning works (like me) and don't know how to create and train neural networks, then this article is for you. !
So what will we create today?
In this tutorial, we will learn how to load pre-trained models from Tensorflow and Caffe through OpenCV's DNN module, and then we will delve into two examples of object recognition based on Node.js and OpenCV.
First we will use Tensorflow's Inception model to identify the objects in the image, and then we will use the COCO SSD model to detect and identify multiple different objects in the same image.
You can find the sample code on my github repository: justadudewhohacks/opencv4nodejs
Tensorflow Inception
The trained Tensorflow Inception model can discern about 1000 classified objects. If you pass the image to the network, it will give the likelihood of each category of the object in the image.
To use the Inception model with OpenCV, we need to load the binary file tensorflow_inception_graph.pb and the category name imagenet_comp_graph_label_strings.txt. You can download inception5h.zip and unzip it to get these files (download link below):
// The path to the path for you to unzip the inception model
Const inceptionModelPath = '../data/dnn/tf-inception'
Const modelFile = path.resolve(inceptionModelPath, 'tensorflow_inception_graph.pb');
Const classNamesFile = path.resolve(inceptionModelPath, 'imagenet_comp_graph_label_strings.txt');
If (!fs.existsSync(modelFile) || !fs.existsSync(classNamesFile)) {
Console.log('Exit: inception model not found');
Console.log ('Download model from https://storage.googleapis.com/download.tensorflow.org/models/inception5h.zip');
Return;
}
// read classNames and store them in an array
Const classNames = fs.readFileSync(classNamesFile).toString().split("");
// Initialize tensorflow inception module from modelFile
Const net = cv.readNetFromTensorflow(modelFile);
Classified items in the image
In order to classify the items in the image, we will write the following helper functions:
Const classifyImg = (img) => {
// The inception model uses 224 x 224 images,
// So we adjust the size of the input image,
// and use white pixels to fill in the image
Const maxImgDim = 224;
Const white = new cv.Vec(255, 255, 255);
Const imgResized = img.resizeToMax(maxImgDim).padToSquare(white);
// The network accepts blobs as input
Const inputBlob = cv.blobFromImage(imgResized);
net.setInput(inputBlob);
// Forward input to the entire network,
// will return a 1xN matrix classification result that contains the confidence for each category
Const outputBlob = net.forward();
// Find all tags that are greater than the minimum confidence
Const minConfidence = 0.05;
Const locations =
outputBlob
.threshold(minConfidence, 1, cv.THRESH_BINARY)
.convertTo(cv.CV_8U)
.findNonZero();
Const result =
Locations.map(pt => ({
Confidence: parseInt(outputBlob.at(0, pt.x) * 100) / 100,
className: classNames[pt.x]
}))
// Sort by confidence
.sort((r0, r1) => r1.confidence - r0.confidence)
.map(res => `${res.className} (${res.confidence})`);
Return result;
}
This function does these things:
Prepare input image
The Tensorflow Inception network accepts 224x224 input images. So we resize the image so that its maximum size is 224, then fill it with white pixels.
Let the image go through the network
We can create a blob directly from the image, then call net.forward() to propagate the input forward and then get the output blob.
Extract the result from the output blob
For commonality, the expression of the output blob is directly a matrix (cv.Mat), and its dimensions depend on the model. This is simple under Inception. A blob is simply a 1xN matrix (where N is equal to the number of categories) and describes the probability distribution for all classes. Each entry is a floating-point number that represents the confidence level of the corresponding classification. The sum of all entries is 1.0 (100%).
We want to take a closer look at the classification of the most likely image, so we look at all confidence levels greater than minConfidence (5% in this case). Finally, we sort the results based on confidence and return the className and confidence pairs.
test
Now we will read some sample data that we want to identify on the network:
Const testData = [
{
Image: '../data/banana.jpg',
Label: 'banana'
},
{
Image: '../data/husky.jpg',
Label: 'husky'
},
{
Image: '../data/car.jpeg',
Label: 'car'
},
{
Image: '../data/lenna.png',
Label: 'lenna'
}
];
testData.forEach((data) => {
Const img = cv.imread(data.image);
Console.log('%s: ', data.label);
Const predictions = classifyImg(img);
predictions.forEach(p => console.log(p));
Console.log();
cv.imshowWait('img', img);
});
The output is: (You can refer to the picture at the beginning of this article)
Banana:
Banana (0.95)
Husky:
Siberian husky (0.78)
Eskimo dog (0.21)
Car:
Sports car (0.57)
Racer (0.12)
Lenna:
Sombrero (0.34)
Cowboy hat (0.3)
very funny. We got a very accurate description of the image of the Iggy and the bananas. For a car image, the specific category of the car is not accurate, but the model does recognize the car in the image. Of course, the network cannot be trained on an infinite classification, so it does not return a “women†description for the last image. However, it does recognize the hat.
COCO SSD
Well, the model performs well. But how do we deal with images that contain multiple objects? To identify multiple objects in a single image, we will use the Single Shot Multibox Detector (SSD). In our second example, we will look at an SSD model trained on a COCO (Common Object in Context) data set. The model we used was trained on 84 different categories.
This model comes from Caffe, so we will load the binary VGG_coco_SSD_300x300_iter_400000.caffemodel and the protoxt file deploy.prototxt:
// Replace the path for you to unzip the coco-SSD model
Const ssdcocoModelPath = '../data/dnn/coco-SSD_300x300'
Const prototxt = path.resolve(ssdcocoModelPath, 'deploy.prototxt');
Const modelFile = path.resolve(ssdcocoModelPath, 'VGG_coco_SSD_300x300_iter_400000.caffemodel');
If (!fs.existsSync(prototxt) || !fs.existsSync(modelFile)) {
Console.log('Exit: cannot find ssdcoco model');
Console.log('Download model https://drive.google.com/file/d/0BzKzrI_SkD1_dUY1Ml9GRTFpUWc/view' from the following URL);
Return;
}
// Initialize the ssdcoco model from prototxt and modelFile
Const net = cv.readNetFromCaffe(prototxt, modelFile);
Classification based on COCO
Our classification function is almost the same as the Inception-based classification function, but this time the input will be a 300x300 image and the output will be a 1x1xNx7 matrix.
Const classifyImg = (img) => {
Const white = new cv.Vec(255, 255, 255);
// ssdcoco model accepts 300 x 300 images
Const imgResized = img.resize(300, 300);
// The network accepts blobs as input
Const inputBlob = cv.blobFromImage(imgResized);
net.setInput(inputBlob);
// Forward input to the entire network,
// will return 1x1xNxM matrix as the classification result
Let outputBlob = net.forward();
// Extract NxM matrix
outputBlob = outputBlob.flattenFloat(outputBlob.sizes[2], outputBlob.sizes[3]);
Const results = Array(outputBlob.rows).fill(0)
.map((res, i) => {
Const className = classNames[outputBlob.at(i, 1)];
Const confidence = outputBlob.at(i, 2);
Const topLeft = new cv.Point(
outputBlob.at(i, 3) * img.cols,
outputBlob.at(i, 6) * img.rows
);
Const bottomRight = new cv.Point(
outputBlob.at(i, 5) * img.cols,
outputBlob.at(i, 4) * img.rows
);
Return ({
className,
Confidence,
topLeft,
bottomRight
})
});
Return results;
};
I'm not quite sure why the output is a 1x1xNx7 matrix, but we actually only care about the Nx7 part. We can use the flattenFloat tool function to map the third and fourth dimensions to the 2D matrix. Compared to the Inception output matrix, this time N does not correspond to each category but each detected object. In addition, there are 7 entries for each object.
Why are 7 items?
Remember, the problems we encountered here are a bit different from before. We want to detect multiple objects in a single image, so we can't just give the confidence of each classification. What we actually want is a rectangle that indicates the position of each object in the graph. The seven entries are:
I actually have no idea
Classification labels for objects
Classification confidence
Left side of the rectangle x
The bottom of the rectangle y
Right side of the rectangle x
y at the top of the rectangle
The output matrix gives us a lot of information about the results, which looks pretty neat. We can also filter the results again based on confidence and draw a border around each recognized object in the image.
Look at its effect!
For the sake of brevity, I will skip drawing rectangular code and other visual code. If you want to know exactly how to do it, you can visit the github repository mentioned earlier.
Let's pass in a car image to the network, then filter the results to see if the car classification is detected:

Great! Let's raise the difficulty below. Let's try...a breakfast table?
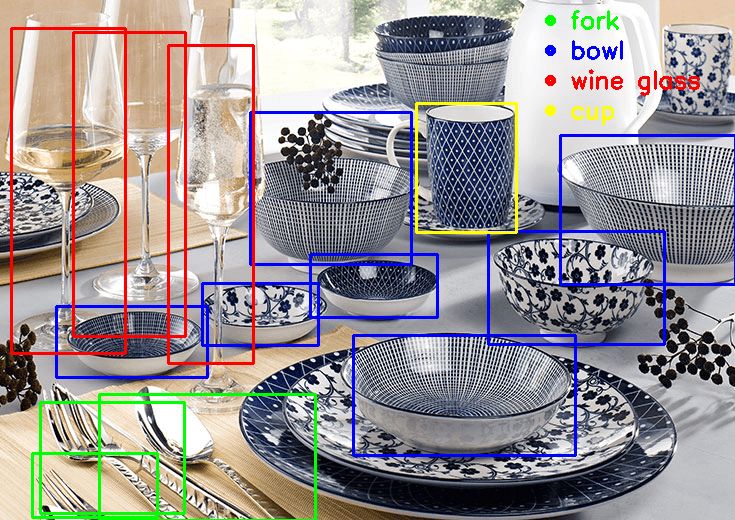
not bad!
ZGAR electronic cigarette uses high-tech R&D, food grade disposable pod device and high-quality raw material. All package designs are Original IP. Our designer team is from Hong Kong. We have very high requirements for product quality, flavors taste and packaging design. The E-liquid is imported, materials are food grade, and assembly plant is medical-grade dust-free workshops.
Our products include disposable e-cigarettes, rechargeable e-cigarettes, rechargreable disposable vape pen, and various of flavors of cigarette cartridges. From 600puffs to 5000puffs, ZGAR bar Disposable offer high-tech R&D, E-cigarette improves battery capacity, We offer various of flavors and support customization. And printing designs can be customized. We have our own professional team and competitive quotations for any OEM or ODM works.
We supply OEM rechargeable disposable vape pen,OEM disposable electronic cigarette,ODM disposable vape pen,ODM disposable electronic cigarette,OEM/ODM vape pen e-cigarette,OEM/ODM atomizer device.

Disposable Vape, bar 3000puffs, ZGAR bar disposable, Disposable E-cigarette, OEM/ODM disposable vape pen atomizer Device E-cig, ZGAR 25 Vape
ZGAR INTERNATIONAL(HK)CO., LIMITED , https://www.oemvape-pen.com