Google has developed an algorithm to deal with the rapid growth of data processing. Later, according to the idea of ​​an algorithm, someone developed an open source software framework called Hadoop. As more and more organizations and individual developers continue to make improvements in the development of the framework, Hadoop has formed a family product that has become the most successful at the moment. Popular distributed big data processing framework.
Hadoop is favored by many organizations because there are two major factors:
First, ultra-large-scale data processing, usually 10TB or more;
Second, ultra-complex calculations, such as statistics and simulation.
Hadoop plays a major role in many application scenarios, such as large-scale statistics, ETL data mining, big data intelligence analysis, and machine learning.

What is the difference between Hadoop and traditional SQL relational data storage?
Hadoop Schema on read, the traditional SQL is the write-once mode (Schema on write). Traditional database storage checks the data, you need to check the table structure definition must be matched before the write (write), otherwise it will error . Hadoop is that you have ever taken any data format and I will store it for you. As long as you give me an interface program to read this data, it will only check if you use this data.
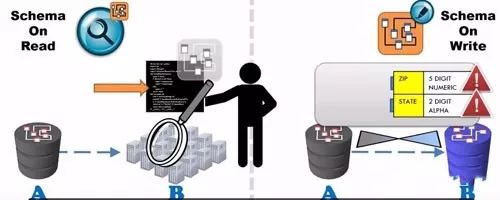
Schema on Read on the left and Schema on Write on the right. The right data format is incorrect, and the left is more concerned with the rules for reading data. Hadoop is a distributed database, and most of the SQL is stored centrally.
For example: There may be thousands of server nodes in the WeChat background for storing WeChat chats. Suppose my chats are distributed on 60 different service nodes. For relational databases, they are concentrated in multiple tablespaces.
If I search for one of my chats, Hadoop will divide the search task into multiple load-balanced search tasks running on 60 nodes. Traditional SQL searches storage space one by one until it is completely traversed. If not completely searched, will return the search results? Hadoop's answer is YES, while traditional SQL will be NO.
The Hadoop family of products, Hive, allows customers who do not know much about SQL to develop queries that are basically the same as SQL.
Hadoop data write, backup, delete operations
First, data write
When the client wants HDFS to write data, it is divided into the following processes:
The client caches data into a local temporary file;
When the local temporary file reaches the block size limit in HDFS, the client accesses the Namenode. Namenode inserts the file name into the HDFS namespace and allocates the corresponding storage location.
The Namenode communicates with the assigned Datanode, determines that the storage location is available, and then returns the storage location information to the client;
The client transfers the local temporary file to the Datanode.
When the write file ends and the temporary file is closed, the existing temporary data is transferred to the Datanode and the Namenode write data is notified;
The Namenode changes the file to a persistent consistency state, which means logging the operation to the log EditLog. If Namenode collapses at this time, the file information is lost.
The main feature of the above process is that the write data is first cached locally and communicates with the Datanode before it reaches the block size limit. The advantage of this is that it avoids the continuous occupation of network bandwidth in the process of the customer writing data, which is very critical for handling the writing of large amounts of data by multiple users.
Second, data backup
The data is written along with the backup of this data block. The process is as follows:
When the client's temporary data reaches a block, it communicates with the Namenode to obtain a set of Datanode addresses. These Datanodes are used to store the data block;
The client first sends the data block to a Datanode. The Datanode accepts 4kb as the unit. We refer to these small units as cache pages (refer to the Linux pipeline file);
For the first Datanode receiving data, it writes the data in the cached page to its own file system. On the other hand, it transfers these cached pages to the next Datanode.
Repeat 3, the second Datanode in turn stores the cached page in the local file system and sends it to the third Datanode.
If the number of backups in HDFS is set to 3, then the third Datanode only needs to store the cached pages.
In the above process, the data blocks flow from the client to the first Datanode, and then to the second, from the second to the third. The whole process is a pipeline process with no pause in the middle. So HDFS calls it Replication Pipelining.
Why not use the client to write data to multiple Datanodes at the same time? In fact, we can guess from the Pipelining this name, the cache files used by the client and Datanode are pipeline files, which only support one read.
Third, data deletion
HDFS data deletion is also more characteristic, not directly deleted, but first placed in a similar recycle bin (/trash), available for recovery.
HDFS will rename and move to /trash the file that the user or application wants to delete. After a certain period of time expires, HDFS will remove it from the file system and modify it by Namenode. Metadata information. And only at this time, the related disk space on the Datanode can be saved. That is, when the user requests to delete a file, it cannot immediately see the increase of HDFS storage space, and wait until a certain period of time (the current default 6 hours).
For backup data, it sometimes needs to be deleted. For example, if the user cuts down the number of Replicaions as needed, then the redundant data backup will be deleted in the next Beatheart contact, and it will be deleted for the Datanode receiving the delete operation. The backup block is also put into /trash first, and then deleted after a certain time. Therefore, there will be a certain delay in the viewing of disk space.
So how to immediately delete the file completely, you can use the Shell command provided by HDFS: bin/hadoop dfs expunge empty /trash.
Whether the game can be played smoothly depends on the low latency of the projector, whether it can be optimized to within 30ms, or within 50ms, which is difficult for non-professionals to perceive. However, the cable and network speed and the configuration of the computer (game console) have an impact on the game delay, so you can't completely throw the pot to the display device.
The first is the problem of memory. Be sure to choose a larger one, the bigger the better, otherwise the screen will freeze. The second is that the resolution must be above 1080p, otherwise the details of the projected game screen will not be clear, which will greatly affect the game experience and viewing experience. The other is about motion compensation. The game screen is generally faster for animation playback. It must be equipped with motion compensation, otherwise the screen will be stuck.
gaming projector,gaming mini projector,gaming projector best buy,4k gaming projector hdmi 2.1,best gaming mini projector
Shenzhen Happybate Trading Co.,LTD , https://www.happybateprojectors.com