Deep learning is only a computer vision tool, not a cure for all diseases. Do not use it blindly because of the popularity. Traditional computer vision techniques can still show their talents. Understanding them can save you a lot of time and troubles; and mastering traditional computer vision can really make you do better in deep learning. This is because you can better understand the internal conditions of deep learning and perform pre-processing steps to improve deep learning results.
The inspiration for this article also comes from a common question in the forum:
Has deep learning replaced traditional computer vision?
Or to say something else:
Since deep learning seems so effective, is it still necessary to learn traditional computer vision techniques?
This question is very good. Deep learning has indeed revolutionized computer vision and artificial intelligence. Many problems that once seemed to be difficult, now machines can be better than human beings. Image classification is the best evidence. Indeed, as previously mentioned, deep learning has the responsibility to incorporate computer vision into the industry landscape.
But deep learning is still only a tool for computer vision, and it is obviously not a panacea for solving all problems. Therefore, this article will elaborate on this. In other words, I will explain why traditional computer vision technology is still very useful and worthy of our continued learning and teaching.
This article is divided into the following sections/arguments:
Deep learning requires big data
Deep learning will sometimes be overdone
Traditional computer vision will increase your level of deep learning
Before entering the text, I think it is necessary to explain in detail what is "traditional computer vision", what is deep learning, and its revolutionary nature.
background knowledge
Before deep learning occurs, if you have a job such as image classification, you will perform a step called "feature extraction" processing. The so-called "feature" is the "interesting", descriptive, or small part of the information provided in the image. You will use a combination of what I call "conventional computer vision technology" in this article to find these features, including edge detection, corner detection, object detection, and so on.
When using these techniques related to feature extraction and image classification, as many features as possible are extracted from the images of a class of objects (eg, chairs, horses, etc.) and are considered as "defines" for such objects. "(called "word bag"). Next you search for these "definitions" in other images. If there is a significant portion of the feature in the bag of words in another image, the image is classified as containing the classification of that particular object (eg, chair, horse, etc.).
The difficulty with this feature extraction method for image classification is that you must choose which features to look for in each image. As the number of categories you are trying to distinguish starts to grow, say, more than 10 or 20, it becomes very cumbersome and even difficult to achieve. Are you looking for corner points? edge? Still texture information? Different categories of objects are best described by different types of features. If you choose to use a lot of features, you have to deal with a lot of parameters, but also need to fine-tune it yourself.
Deep learning introduces the concept of "end-to-end learning", which (in short) lets the machine learn to find features in each specific category of objects, namely the most descriptive and prominent features. In other words, let the neural network discover potential patterns in various types of images.
Therefore, with end-to-end learning, you no longer need to manually decide which traditional machine vision technology to use to describe features. The machine does all this for you. Wired magazine wrote:
For example, if you want to teach a [deep] neural network to identify a cat, you don't have to tell it to look for beards, ears, hair, or eyes. You only have to show it the images of thousands of cats, which will naturally solve the problem. If it always mistakes the fox for a cat, you don't have to rewrite the code. You just need to continue training it.
The figure below illustrates this difference between feature extraction (using traditional computer vision) and end-to-end learning:
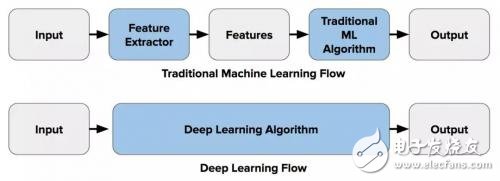
The above is the background introduction. Now we will discuss why traditional computer vision is still indispensable, and learning it will still be of great benefit.
Deep learning requires a lot of data
First, deep learning requires data, a lot of data. The training of the well-known image classification models mentioned above is based on a large dataset. The top three training data sets are:
ImageNet - 1.5 million images, 1000 object categories/categories;
COCO - 2.5 million images, 91 object classifications;
PASCAL VOC - 500,000 images, 20 object categories.
But a poorly trained model is likely to perform poorly outside of your training data because the machine does not have insight into the problem and cannot summarize it without seeing the data. And it's too difficult for you to look inside the training model and make manual adjustments, because a deep learning model has millions of parameters inside - each parameter is adjusted during training. To some extent, a deep learning model is a black box.
Traditional computer vision is completely transparent, allowing you to better evaluate whether your solution is still effective outside of the training environment. Your insights into the problem can be put into your algorithm. And if anything goes wrong, you can also easily figure out what needs to be adjusted and where to adjust.
Deep learning is sometimes overdone
This is probably my favorite reason to support the study of traditional computer vision technology.
It takes a long time to train a deep neural network. You need specialized hardware (such as high-performance GPUs) to train the latest and most advanced image classification models. Do you want to train on your nice laptop? Go on a week off, and when you come back, training may still not be completed.
In addition, what if your training model performs poorly? You have to go back to the origin and redo the whole job with different training parameters. This process may be repeated hundreds of times.
But sometimes all of these are completely unnecessary. Because traditional computer vision technology can solve problems more efficiently than deep learning, it uses less code. For example, one project I once participated in was to check whether there was a red spoon in each jar that passed the conveyor belt. Now you can train a deep neural network to detect spoons through the long-term process described earlier, or you can write a simple red threshold algorithm (mark any pixel with a certain range of red as white, all Other pixels are marked in black) and then calculate how many white pixels there are. Simply, you can get it in an hour!
Mastering traditional computer vision techniques may save you a lot of time and reduce unnecessary annoyances.
Traditional computer vision will enhance your deep learning skills
Understanding traditional computer vision can actually help you do better in deep learning.
For example, the most commonly used neural network in the field of computer vision is a convolutional neural network. But what is convolution? Convolution is actually a widely used image processing technique (eg, Sobel edge detection). Knowing this can help you understand exactly what is happening inside the neural network, so that you can design and fine tune it to better solve your problems.
One more thing is called preprocessing. The data you enter into the model is often processed in such a way as to prepare for the next training. These preprocessing steps are mainly accomplished through traditional computer vision techniques. For example, if you don't have enough training data, you can do a process called data enhancement. Data enhancement refers to randomly rotating, moving, and cropping images in your training dataset to create "new" images. By performing these computer vision operations, you can greatly increase your training data volume.
in conclusion
This article explains why deep learning has not replaced traditional computer vision techniques, and the latter is still worth learning and teaching. First, this article focuses on the issue that deep learning often requires a lot of data to perform well. Sometimes there is not a lot of data, and traditional computer vision can be used as an alternative in this case. Second, deep learning occasionally overdoes certain tasks. In these tasks, standard computer vision can solve problems more efficiently than deep learning and use less code. Third, mastering traditional computer vision can really make you better at deep learning. This is because you can better understand the internal conditions of deep learning and perform pre-processing steps to improve deep learning results.
In short, deep learning is only a tool for computer vision, not a cure for all diseases. Do not use it blindly because of fashion. Traditional computer vision techniques can still show their talents. Understanding them can save you a lot of time and trouble.
Desktop style 12v and 24v series can be used in many different electronics. EMC, LVD, FCC, RoHS are available in our company. OEM and ODM are available, samples are free for testing, all our products have 2 years warranty.
Our products built with input/output overvoltage protection, input/output overcurrent protection, over temperature protection, over power protection and short circuit protection. You can send more details of this product, so that we can offer best service to you!
Led Adapter, Lcd Adapter,Speaker Power Adapter,Lcd Power Supply
Shenzhen Waweis Technology Co., Ltd. , https://www.laptopsasdapter.com