In life or work, people often face a variety of choices, very confused and confused, and correct decision-making is very important. Similarly, there are also decision-making problems in artificial intelligence research. Today, I will talk to you about the decision tree of artificial intelligence.
DecisionTree is a common class of machine learning methods. The location of the decision tree (DT) in artificial intelligence:
Artificial Intelligence -> Machine Learning -> Supervised Learning -> Decision Tree.
In machine learning, the decision tree (DT) is a predictive (decision) model that represents a mapping between object properties and object values. The decision tree algorithm uses a tree structure to build a decision model based on the attributes of the data.

What is a decision tree?
The decision tree (DT) is a decision analysis method that evaluates the project risk and judges its feasibility by constructing a decision tree to obtain the probability that the expected value of the net present value is greater than or equal to zero, based on the known probability of occurrence of various situations. A graphical method of using probabilistic analysis. Since this decision branch is drawn like a tree, it is called a decision tree. Machine learning techniques that generate decision trees from data are called decision tree learning.
By definition we know that the decision tree (DT) is a tree structure in which each node in the tree represents an object, and each forked path represents a possible attribute value, and each leaf node is Corresponds to the value of the object represented by the path from the root node to the leaf node. There are two types of nodes: internal nodes and leaf nodes. Internal nodes represent a feature, attribute, or test on an attribute. Each branch represents a test output, and a leaf node represents a category. Decision trees (DT) are generally generated from the top down. Each decision or event (ie, a natural state) can lead to two or more events, resulting in different outcomes.
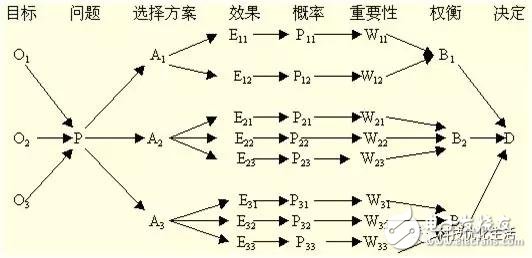
Decision Tree (DT) is a very common classification method, also known as classification tree. It is a kind of supervised learning, that is, given a bunch of samples, each sample has a set of attributes and a category, these categories are determined in advance, then learn to get a classifier, this classifier can give new objects The correct classification. Therefore, decision trees are often used to solve classification and regression problems.
Decision tree components:
1) Decision node: Represented by the block node â–¡ is the choice of several possible options, that is, the best choice for the final selection. If the decision is a multi-level decision, there may be multiple decision points in the middle of the decision tree, and the decision point at the root of the decision tree is the final decision plan.
2) Scheme branch: a number of fine branches are drawn from the nodes, each of which represents a scheme called a scheme branch
3) State node: represented by a circular node â—‹, representing the economic effect (expectation value) of the alternative, through the comparison of the economic effects of each state node, the best solution can be selected according to certain decision criteria.
4) Probability branch: The branch drawn by the state node is called the probability branch, and the number of probability branches indicates the number of natural states that may appear. The content of the status and the probability of its occurrence should be indicated on each branch.
5) Result node: Indicated by the triangular node â–³, the benefit value or loss value obtained by each scheme in various natural states is marked on the right end of the result node.

In short, the decision tree is generally composed of decision nodes, program branches, state nodes, probability branches, and result nodes, so that the tree diagram is composed of left to right or top-down, from simple to complex, forming a tree. Network Diagram.
Decision tree learning process:
The decision tree learning process (tree building process) includes feature selection, decision tree generation and pruning process. The decision tree learning algorithm usually recursively selects the optimal features and segments the data set with the optimal features. At the beginning, the root node is constructed and the optimal feature is selected. The feature is divided into several subsets with several values. Each subset recursively calls this method, returns the node, and the returned node is the child of the previous layer. point. Until all features have been used up, or the data set has only one-dimensional features. In addition, the random forest classifier combines many decision trees to improve the accuracy of the classification.

The main challenge of the decision tree building process is to determine which attributes act as root nodes and nodes at each level. Handling these requires knowing the choice of attributes. There are currently two different methods of attribute selection (information gain and Gini index) to identify these attributes. When the information gain is used as a criterion, it is assumed that the attribute is classified; for the Gini coefficient, the attribute is assumed to be continuous.
Film capacitors are electrical capacitors with an insulating plastic film as the dielectric, sometimes combined with paper as carrier of the electrodes. These plastic films are sometimes metalized and are available in the market under the name metalized film capacitor,these capacitors are sometimes also called plastic capacitors.
Film Capacitor,X-Ray equipment Capacitor,Axial Polyester Capacitor,Polypropylene High Voltage Capacitor
XIAN STATE IMPORT & EXPORT CORP. , https://www.shvcomponents.com