Deep networks, as the name suggests, are networks with "many" layers.
So how many layers are the depth? There may not be a clear answer to this question. In a sense, the question is similar to "how much sand can be counted as sand dunes." However, in general, we call a network with two or more hidden layers called a deep network. In contrast, a network with only one hidden layer is generally considered a "shallow network." Of course, I suspect that we may experience inflation in the network layer. Ten years later, people may think that the network of 10 hidden layers is a "shallow network", which is only suitable for kindergarten children to practice. Informally, "depth" implies that dealing with such a network is difficult.
However, the question you really want to ask is actually why more hidden layers are useful?
What is surprising is that no one knows the real reason. I will briefly introduce some common explanations below, but the truth of these explanations is not convincing. We can't even be sure that more layers really work.
I say this is surprising because deep learning is very popular in the industry, and it breaks records in many fields such as image recognition, Go, and automatic translation. However, we are still unclear why the effect of deep learning is so good.
The universal approximation theorem shows that a "shallow" neural network (a neural network with a hidden layer) can approximate any function, that is, a shallow neural network can learn anything in principle. It is therefore possible to approximate many nonlinear activation functions, including the ReLu functions that are now widely used in deep networks.
In this case, why do you still need a deep network?
Ok, a plain answer is because they work better. The picture below is a picture of Goodfellow waiting for Deep Learning to show that for a particular problem, the more hidden layers, the higher the accuracy. This phenomenon can also be observed in many other tasks and areas.
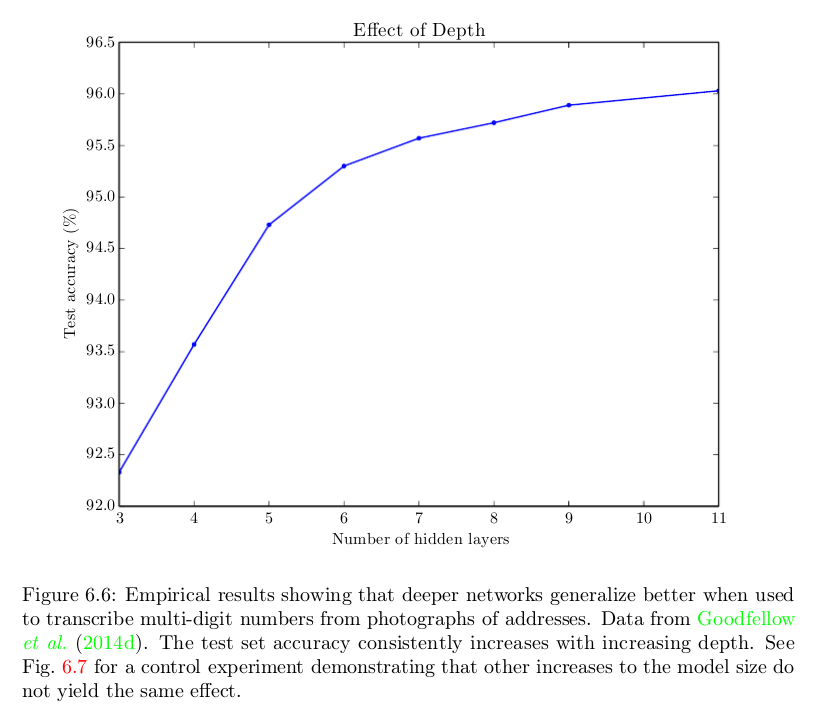
We know that a shallow network can be as good as a deep network, but this is often not the case. The problem is coming - why? Possible answers include:
Maybe a shallow network needs more neurons than a deep network?
Maybe our current algorithm is not suitable for training shallow networks?
Maybe the problem we usually try to solve is not suitable for shallow networks?
other reasons?
Goodfellow waited for Deep Learning to provide some reasons for the first and third answers above. The number of neurons in a shallow network will increase geometrically as the complexity of the task increases. Therefore, shallow networks have a role to play and become very large, probably larger than deep networks. The reason for this reason is that many papers have shown that in some cases, the number of neurons in a shallow network will increase geometrically as the complexity of the task increases, but we are not sure whether this conclusion applies to such things as MNIST classification and tasks like Go.
Regarding the third answer, the book Deep Learning says so:
Choosing a depth model encodes a very general belief that the function we want to learn should involve a combination of several simpler functions. From the perspective of characterization learning, we believe that the problem of learning involves finding the underlying factors of a set of differences that can be further described by the underlying factors of other simpler differences.
I think the current "consensus" is why the combination of the first and third answers above is valid for deep networks.
But this is far from proof. The 150+ layer residual network proposed in 2015 won the championship of several image recognition competitions. This is a huge success and it seems to be an irresistible deeper and better argument.
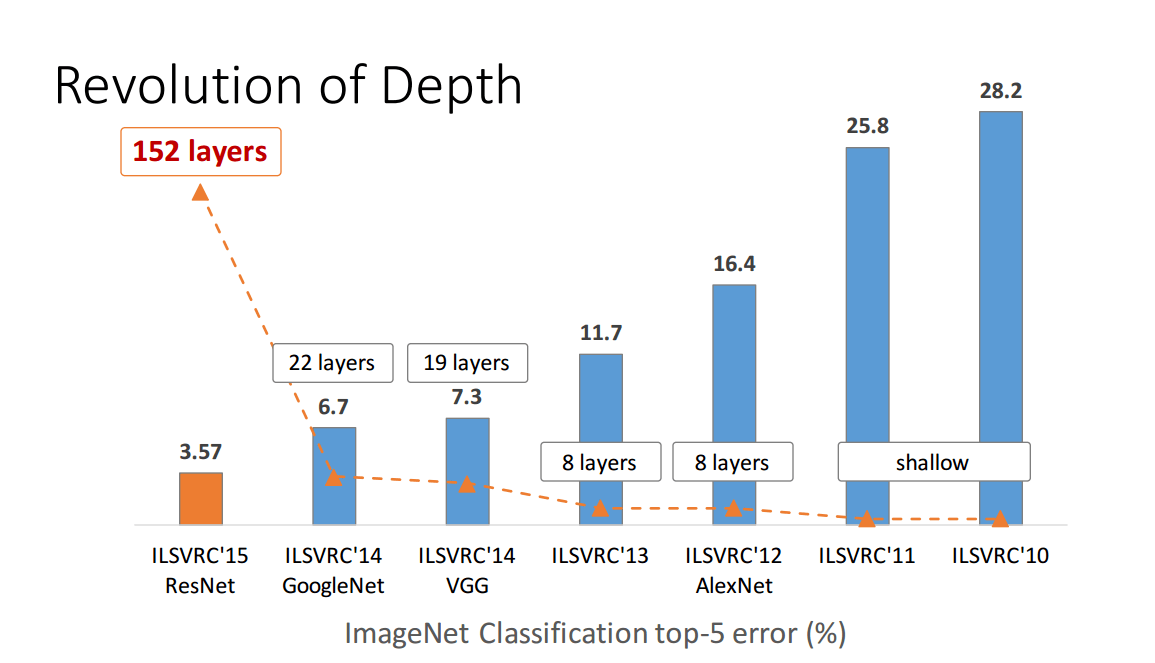
However, the Wide Residual Networks proposed in 2016 surpassed the 150+ layer residual network with a 16-layer network.
Ba and Caruana's paper "Do Deep Nets Really Need to be Deep?" published in 2014 (Deep network really needs so deep?) Through a model compression scheme, using a shallow network to simulate a trained deep network, for a certain For deep networks, the shallow networks that simulate them can perform equally well, although training shallow networks directly on the corresponding data sets does not achieve this.
So maybe the real answer is the second answer mentioned above.
As I said at the beginning, no one is sure that they know the real answer.
The progress in deep learning has been amazing for the past 10 years! However, most of the progress has been made through trial and error, and we still lack a basic understanding of what makes deep networks work. Even the question of what is the key to configuring an efficient deep network is often changed.
Geoffrey Hinton has worked on neural networks for 20+ years, but has not received much attention for a long time. Until 2006, a series of groundbreaking papers were published that introduced effective techniques for training deep networks—unsupervised pre-training before the gradient falls. For a long time, people thought that unsupervised pre-training was the key.
Then, in 2010 Martens showed that Hessian-free optimization works better. In 2013, Sutskever et al. showed that the random gradient drop plus some very clever tricks can perform better. At the same time, in 2010, everyone realized that using ReLu instead of Sigmoid can significantly improve the performance of gradient descent. In 2014, dropout was proposed. In 2015, a residual network was proposed. More and more effective methods of training networks have been proposed, and the crucial insights 10 years ago are often boring today. Most of these are driven by trial and error, and we don't know much about why a certain technique works so well.
We don't even know why deep networks reach the plateau; people blamed the minimum for 10 years ago, but now people don't see it this way (the gradient tends to keep a large value when it reaches the plateau). This is a very basic question about deep networks, and we don't even know it.
Mini 500Puffs,Mini 500Puffs Disposable,Mini 500Puffs Disposable Vape,Mini 500Puffs Grape
Lensen Electronics Co., Ltd , https://www.lensenvape.com