When you see a picture, we can easily guess the stereoscopic appearance of the object in the picture, but can the machine do it? Researchers at the University of California, Berkeley, have developed a framework that allows machines to restore stereoscopic prototypes with a single image and add natural texture patterns. The following is the compilation of the original thesis by the wisdom, followed by the address of the paper and the video of the experimental results.
We developed a learning framework that restores the 3D shape, camera angle, and texture of objects in a graph with a single image. The shape is represented by a deformable 3D mesh model.
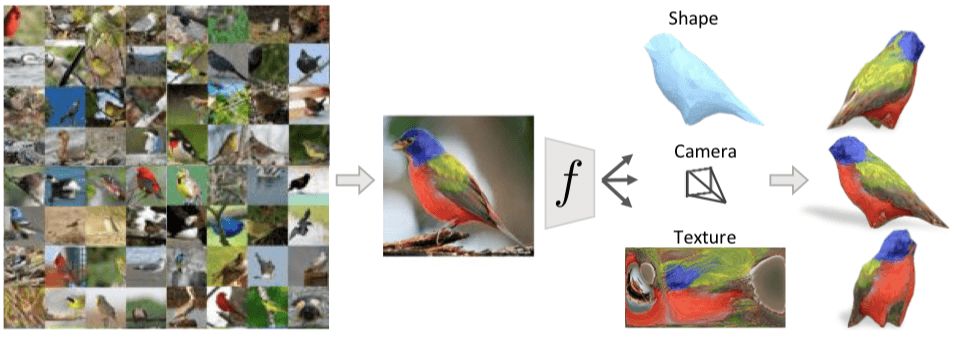
There are many birds in the picture above. Even if we are seeing the two-dimensional bird on this picture for the first time, we can still infer its approximate 3D shape, understand the angle of shooting, and even guess from another angle. See what it will be like. We can do this because the birds we've seen before give us a rough outline of strange birds, and this knowledge helps us restore the 3D structure of these cases.
In this article, we show a computational model that can infer a 3D representation from a single image. As shown in the above image, the learning process requires only an annotated 2D image, including the target object's category, foreground mask, and Semantic key tags.
Our goal is to generate a predictor fθ (parameterized to a CNN) that infers the 3D structure of the target object from a single photo I. In this project we want to represent the shape of the object in a 3D grid. This representation has more advantages than other methods (such as probabilistic volumetric grids), such as simulation of textures, corresponding reasoning, surface level inference, and Explanatory.
The framework we propose is shown below. The input image passes through an encoder and arrives at a representation consisting of three modules that predict the camera position, object shape and pattern parameters.
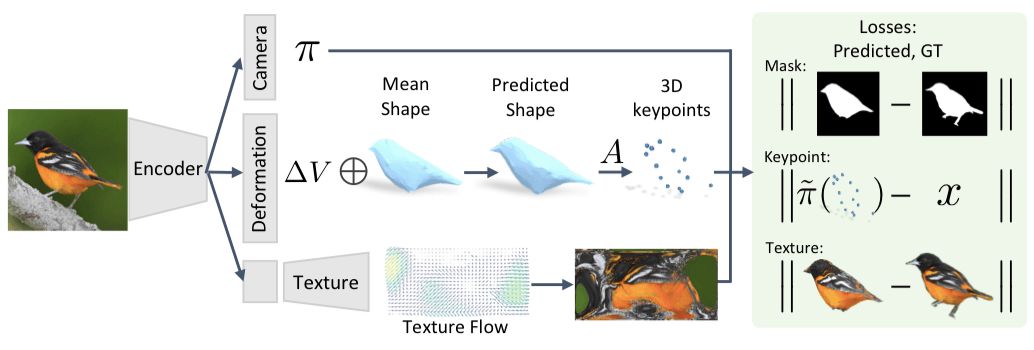
Use the model to infer the 3D representation of the target
First, given an image I, we predict fθ(I)≡(M, π), the mesh M and the camera position π are used to capture the 3D structure of the object. The specific derivation process can be viewed in the original paper. In addition to these direct predictions, we also learned the relationship between grid and category-level semantic focus. When we use a particular category of meshes to represent shapes in a canonical framework, the rules across instances help us find semantically consistent fixed-point locations, implicitly assigning these vertex semantics.
After this step, we use a picture I to infer the corresponding camera position π and shape ∆V. At the same time, we also learn the independent parameters of the examples. The position V of the grid fixed point and the semantic focus A·V are inferred.
Learning from image collections
In order to train fθ, we propose a method that does not rely on the supervision of actual 3D shapes and multi-angle image instances, but learns from image sets with sparse key points and segmentation masks. This setup is more natural and readily available, especially for moving and deformable objects such as birds or other animals. It is very difficult to get a scan of an object or even multiple angles of the same object, but for most objects, it is relatively easy to get a single image.
With an annotated set of images, we train fθ by developing an objective function that contains the loss and a priori associated with the instance. Specific example energy terms can ensure that the predicted 3D structure is consistent with existing masks and key points, and prior knowledge can help generate features such as smoothness. Since we have obtained the general predictive model fθ from many examples, the general structure between the various categories allows us to get meaningful 3D predictions, even if there is only one instance.
Insert pattern prediction
In our formula, all restored shapes have a common 3D mesh structure—each shape is a deformation of the average shape. We can use this property to reduce the pattern in a particular instance to predict the shape of the average pattern. Our average shape is a sphere whose surface pattern can be represented as an image called Iuv whose value is mapped to the surface by a fixed UV mapping (similar to expanding the earth into a plan view).
Thus, we consider this task of predicting patterns as the pixel value of the inferred Iuv. This image can be thought of as a typical appearance space belonging to the target object category. For example, a particular triangle in a predicted shape will always map to a specific area in Iuv, no matter how it is deformed.
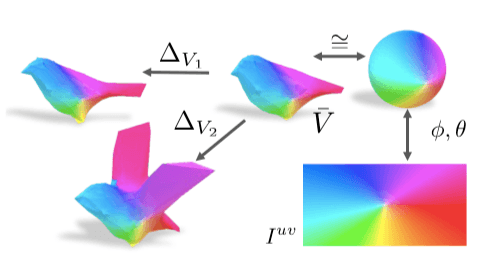
After parameterizing the pattern, the semantic meaning of each pixel in the UV image is consistent, making it easier for the predictive model to take advantage of common patterns, such as the correlation between the back of the bird and the body.
We add a pattern prediction module to the frame by setting up a decoder that converts the potential representation into a space vector of Iuv. Although it is a feasible method to directly calculate the pixel value of Iuv by regression, it usually leads to the generation of blurred images. Instead, we see this task as predicting the appearance flow. Instead of returning the value of the Iuv pixel, we let the module output the pixel color copied from the original input image. as the picture shows:

experiment procedure
After the model was set up, we selected the CUB-200-2011 dataset for experiments with 6,000 training and test images, including 200 species of birds. Each image has a bounding box for labeling, and 14 semantic key points are marked for location, along with a mask for the foreground. We selected nearly 300 images, each of which has fewer than or equal to six key points. In addition, the schematic diagram of each module of the prediction network is shown in Figure 2. The encoder consists of a ResNet-18 pre-trained on ImageNet, followed by a convolution layer.
The resulting reconstruction results on the CUB test set are shown in the figure:

There will be a 360-degree panoramic display in the appendix and in the post-text.
In addition, we replaced the pattern of the target object and replaced the texture on the image with the predicted shape. We found that even though the two views may be different, the converted texture is semantically consistent because the underlying texture image is spatially consistent.

In addition, we did the same experiment on the PASCAL 3D+ dataset for the car and the aircraft. The predicted shape is usually normal, but the pattern will have more errors because there are reflective parts or training data on the car. less:

Conclusion
We show a framework that can predict the 3D structure of an object from a single angle. Although the results are very exciting, we have not proposed a universal solution. Finally, although we can only learn with a single view of an instance, for a scenario with multiple views, our approach may work equally well and produce better results.
Middle-low Level Commercial Sky Curtain
Middle-Low Level Commercial Sky Curtain,Outdoor Football Stadium Led Grille Screen,Transparent Led Grille Screen,Led Display Billboard
Kindwin Technology (H.K.) Limited , https://www.ktlleds.com